Tensor Processing Units (TPUs) are specialized hardware accelerators designed specifically for accelerating machine learning workloads, particularly deep learning models, by optimizing matrix and tensor operations. Unlike GPUs, which offer versatile parallel processing suitable for gaming, graphics rendering, and general-purpose computations, TPUs deliver superior performance and energy efficiency for neural network inference and training tasks. The architectural differences make TPUs the preferred choice in large-scale AI applications requiring high throughput and low latency.
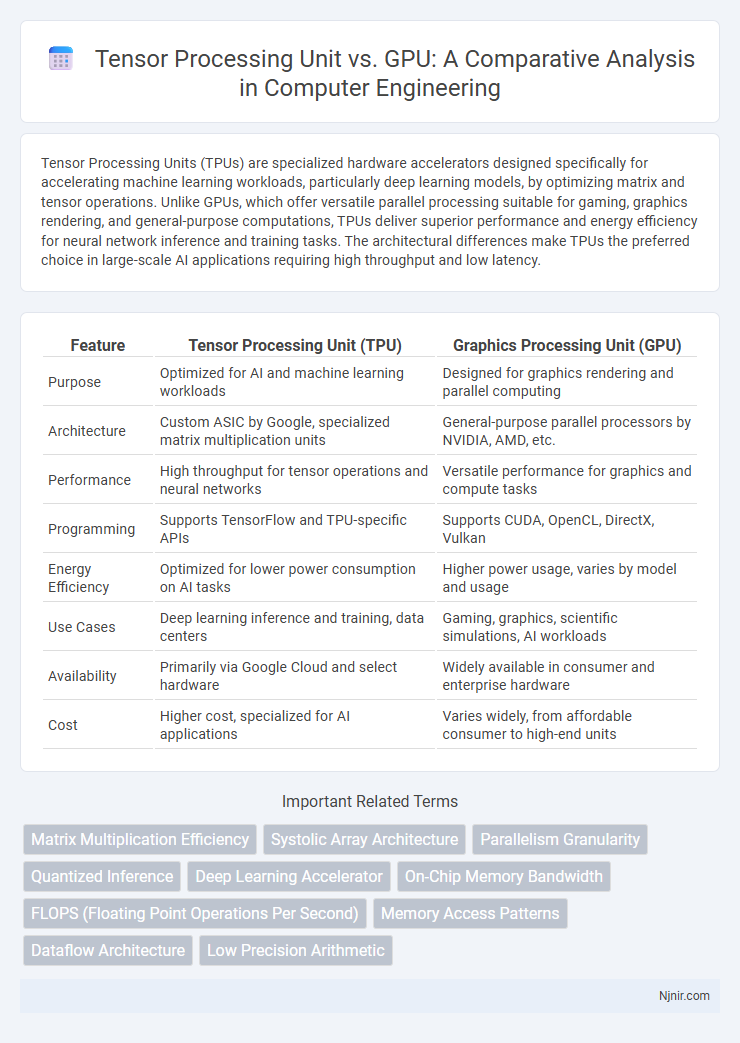
Table of Comparison
| Feature | Tensor Processing Unit (TPU) | Graphics Processing Unit (GPU) |
|---|---|---|
| Purpose | Optimized for AI and machine learning workloads | Designed for graphics rendering and parallel computing |
| Architecture | Custom ASIC by Google, specialized matrix multiplication units | General-purpose parallel processors by NVIDIA, AMD, etc. |
| Performance | High throughput for tensor operations and neural networks | Versatile performance for graphics and compute tasks |
| Programming | Supports TensorFlow and TPU-specific APIs | Supports CUDA, OpenCL, DirectX, Vulkan |
| Energy Efficiency | Optimized for lower power consumption on AI tasks | Higher power usage, varies by model and usage |
| Use Cases | Deep learning inference and training, data centers | Gaming, graphics, scientific simulations, AI workloads |
| Availability | Primarily via Google Cloud and select hardware | Widely available in consumer and enterprise hardware |
| Cost | Higher cost, specialized for AI applications | Varies widely, from affordable consumer to high-end units |
Introduction to Tensor Processing Units and GPUs
Tensor Processing Units (TPUs) are specialized hardware accelerators designed by Google specifically for accelerating machine learning workloads, particularly deep learning models using TensorFlow. Graphics Processing Units (GPUs), originally developed for rendering graphics, have evolved into versatile platforms capable of parallel processing tasks, making them suitable for training and inference in AI applications. TPUs offer optimized performance for matrix operations and reduced precision arithmetic, while GPUs provide flexibility with broader support for diverse AI frameworks and workloads.
Architectural Differences Between TPU and GPU
Tensor Processing Units (TPUs) feature a systolic array architecture optimized specifically for high-throughput matrix multiplications critical in deep learning, whereas GPUs utilize a massively parallel SIMT (Single Instruction, Multiple Threads) architecture designed for a broader range of parallel computing tasks. TPUs achieve higher efficiency in neural network workloads by integrating large matrix multiply units and high-bandwidth memory optimized for tensor operations, while GPUs rely on thousands of CUDA cores with shared memory hierarchies suitable for diverse graphics and compute tasks. The distinct architectural design of TPUs, including their streamlined instruction set focused on tensor computations, contrasts with the more flexible but power-intensive GPU architecture, resulting in TPUs offering superior performance-per-watt for AI inference and training workloads.
Computational Performance: TPU vs GPU
Tensor Processing Units (TPUs) deliver superior computational performance compared to GPUs in specific machine learning tasks, particularly in deep learning model training and inference, due to their specialized architecture optimized for matrix multiplications and high-throughput parallel operations. While GPUs offer versatility across diverse applications and excel in floating-point arithmetic operations with thousands of cores, TPUs leverage custom-designed tensor cores that significantly reduce latency and increase efficiency in processing large-scale neural networks. Benchmark results reveal TPUs achieving up to 15-30x speed improvements over GPUs in key AI workloads, marking them as the preferred choice for accelerating TensorFlow-based environments.
Power Efficiency and Cost Considerations
Tensor Processing Units (TPUs) deliver superior power efficiency compared to GPUs by optimizing matrix multiplication and deep learning workloads, resulting in lower energy consumption for AI tasks. Cost considerations favor TPUs in large-scale machine learning deployments due to their specialized architecture, which reduces operational expenses and accelerates training times. GPUs remain versatile for a wide range of applications, but TPUs provide a more cost-effective and power-efficient solution specifically tailored for neural network inference and training.
Machine Learning Workloads: Which is Better?
Tensor Processing Units (TPUs) excel in accelerating deep learning models, especially for large-scale neural network training and inference, due to their architecture optimized for matrix multiplications and high throughput. Graphics Processing Units (GPUs) offer versatility and superior performance in a wide range of machine learning workloads, including both training and inference, thanks to their parallel processing capabilities and extensive software support like CUDA and TensorFlow. Choice between TPU and GPU depends on workload complexity, model size, and deployment environment, with TPUs often preferred for production-ready deep learning models in cloud infrastructures, while GPUs provide flexibility for research and diverse machine learning applications.
Programming and Software Ecosystem
Tensor Processing Units (TPUs) are specifically designed for accelerating machine learning workloads, tightly integrated with Google's TensorFlow ecosystem, offering optimized performance for deep learning models and seamless deployment in cloud environments. GPUs provide versatile parallel processing capabilities with broad support across multiple frameworks like PyTorch, TensorFlow, and CUDA, making them suitable for diverse applications beyond AI, including graphics rendering and scientific computing. The software ecosystem for TPUs emphasizes high-level APIs and TPU-specific optimizations, whereas GPUs benefit from extensive developer tools, libraries, and a mature programming environment for both AI and general-purpose computing.
Scalability and Deployment Options
Tensor Processing Units (TPUs) offer superior scalability in AI model training by providing high throughput for matrix operations, enabling efficient deployment across cloud environments such as Google Cloud Platform. GPUs excel in flexible deployment across diverse hardware setups, including on-premises data centers and various cloud providers, supporting a wide range of applications beyond deep learning. TPUs are optimized for large-scale neural network workloads, while GPUs maintain versatility with extensive software ecosystem support, influencing deployment strategies based on workload demands.
Use Cases: TPU vs GPU in Real-world Applications
Tensor Processing Units (TPUs) excel in large-scale machine learning tasks, particularly for training and inferencing deep neural networks in natural language processing and image recognition, offering higher efficiency and speed compared to GPUs. GPUs remain versatile for diverse applications including gaming, scientific simulations, and real-time rendering due to their parallel processing architecture. Real-world deployments leverage TPUs in data centers for AI model training at scale, while GPUs support both AI workloads and traditional graphics-intensive tasks across various industries.
Limitations and Challenges of TPU and GPU
Tensor Processing Units (TPUs) face limitations such as reduced flexibility compared to GPUs, being optimized primarily for specific machine learning workloads like matrix multiplications, which restricts their usability for general-purpose computing tasks. GPUs encounter challenges including high power consumption and thermal output, which can lead to increased operational costs and the need for advanced cooling solutions in data centers. Both TPUs and GPUs also struggle with scalability in distributed training scenarios due to communication overhead and synchronization issues between multiple processing units.
Future Trends in AI Accelerators: TPU and GPU
Tensor Processing Units (TPUs) are increasingly optimized for large-scale AI workloads, offering superior performance and power efficiency in deep learning tasks compared to traditional GPUs. Future trends indicate TPUs will integrate more specialized architectures and support broader AI frameworks, while GPUs continue evolving with enhanced parallelism and memory bandwidth to handle diverse AI and graphics workloads. Advancements in hybrid computing approaches combining TPU and GPU capabilities are expected to drive significant improvements in training speed and model accuracy for next-generation AI applications.
Matrix Multiplication Efficiency
Tensor Processing Units deliver up to 15-30 times higher matrix multiplication efficiency than GPUs by leveraging dedicated systolic arrays optimized for large-scale tensor operations.
Systolic Array Architecture
Tensor Processing Units leverage systolic array architecture to accelerate matrix multiplication and deep learning workloads more efficiently than traditional GPUs, which primarily use parallel cores for general-purpose computation.
Parallelism Granularity
Tensor Processing Units (TPUs) achieve finer parallelism granularity than GPUs by optimizing matrix multiplication operations at the hardware level, enabling higher throughput for large-scale neural network computations.
Quantized Inference
Tensor Processing Units (TPUs) deliver significantly faster and more energy-efficient quantized inference for deep learning models compared to GPUs due to their specialized architecture optimized for low-precision arithmetic and matrix operations.
Deep Learning Accelerator
Tensor Processing Units (TPUs) outperform GPUs in deep learning acceleration by offering specialized hardware optimized for matrix multiplications and higher throughput in neural network training and inference tasks.
On-Chip Memory Bandwidth
Tensor Processing Units (TPUs) deliver significantly higher on-chip memory bandwidth than GPUs, enabling faster data transfer rates and improved performance for machine learning workloads.
FLOPS (Floating Point Operations Per Second)
Tensor Processing Units deliver significantly higher FLOPS compared to GPUs by optimizing matrix operations for machine learning workloads.
Memory Access Patterns
Tensor Processing Units optimize memory access patterns through systolic arrays enabling efficient matrix multiplication, while GPUs rely on parallel thread execution with shared and global memory hierarchies to handle diverse access patterns.
Dataflow Architecture
Tensor Processing Units (TPUs) utilize a specialized dataflow architecture optimized for high-throughput matrix multiplications in machine learning tasks, whereas GPUs employ a more general-purpose parallel processing architecture designed for a wider range of graphics and compute workloads.
Low Precision Arithmetic
Tensor Processing Units (TPUs) excel in low precision arithmetic by offering specialized hardware optimized for efficient 8-bit and 16-bit matrix operations, outperforming GPUs in speed and energy efficiency for deep learning inference.
Tensor Processing Unit vs GPU Infographic