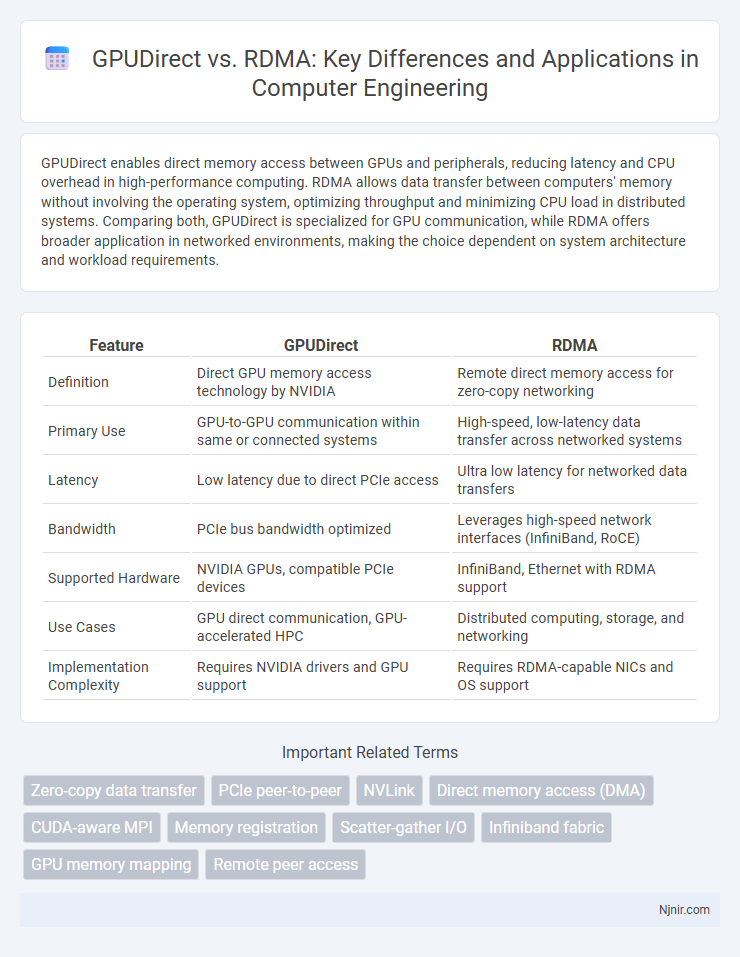
GPUDirect enables direct memory access between GPUs and peripherals, reducing latency and CPU overhead in high-performance computing. RDMA allows data transfer between computers' memory without involving the operating system, optimizing throughput and minimizing CPU load in distributed systems. Comparing both, GPUDirect is specialized for GPU communication, while RDMA offers broader application in networked environments, making the choice dependent on system architecture and workload requirements.
Table of Comparison
| Feature | GPUDirect | RDMA |
|---|---|---|
| Definition | Direct GPU memory access technology by NVIDIA | Remote direct memory access for zero-copy networking |
| Primary Use | GPU-to-GPU communication within same or connected systems | High-speed, low-latency data transfer across networked systems |
| Latency | Low latency due to direct PCIe access | Ultra low latency for networked data transfers |
| Bandwidth | PCIe bus bandwidth optimized | Leverages high-speed network interfaces (InfiniBand, RoCE) |
| Supported Hardware | NVIDIA GPUs, compatible PCIe devices | InfiniBand, Ethernet with RDMA support |
| Use Cases | GPU direct communication, GPU-accelerated HPC | Distributed computing, storage, and networking |
| Implementation Complexity | Requires NVIDIA drivers and GPU support | Requires RDMA-capable NICs and OS support |
Introduction to GPUDirect and RDMA
GPUDirect is a technology developed by NVIDIA that enables direct memory access between GPU memory and third-party devices, significantly reducing latency and CPU overhead in data transfers. RDMA (Remote Direct Memory Access) allows the direct memory transfer between servers over a network without involving the CPU, optimizing throughput and minimizing latency in high-performance computing environments. Both GPUDirect and RDMA are critical for accelerating data-intensive applications by enabling efficient, low-latency communication between GPUs and network or storage devices.
Fundamental Concepts of GPUDirect
GPUDirect enables direct memory access between GPUs and third-party devices, bypassing the CPU to reduce latency and improve data transfer speeds in high-performance computing environments. It leverages NVIDIA's PCIe technology to streamline communication by enabling peer-to-peer data transfers, minimizing CPU involvement and system overhead. This fundamental concept enhances GPU-accelerated applications by allowing efficient, low-latency data movement critical for workloads like AI training and scientific simulations.
Overview of RDMA Technology
RDMA (Remote Direct Memory Access) technology enables direct memory access from the memory of one computer into that of another without involving either one's operating system, improving throughput and reducing latency. This capability facilitates high-performance data transfers in distributed computing environments, crucial for applications such as deep learning and HPC clusters. RDMA leverages network adapters and specialized protocols like InfiniBand, RoCE, or iWARP to achieve zero-copy networking and efficient CPU offload.
Key Differences: GPUDirect vs RDMA
GPUDirect enables direct memory access between GPUs and third-party devices, minimizing latency by bypassing the CPU, while RDMA allows direct data transfer between memory regions of different computers without CPU intervention, typically used in high-performance networking. GPUDirect is specifically designed for GPU communication and acceleration in heterogeneous computing environments, whereas RDMA is a broader technology used in distributed systems for efficient network I/O. Key differences include GPUDirect's focus on GPU-to-device data paths and integration with NVIDIA hardware, contrasted with RDMA's protocol-agnostic network-based memory access across different machines.
Use Cases in Modern Data Centers
GPUDirect enables direct memory access between GPUs and peripherals, significantly accelerating AI training and real-time data analytics by reducing latency and CPU overhead. RDMA provides high-throughput, low-latency networking for data center applications such as high-performance computing (HPC), distributed storage, and virtualization, optimizing server-to-server communications. Modern data centers leverage GPUDirect for GPU-accelerated workloads while employing RDMA to enhance network efficiency and scalability across server clusters.
Performance Comparison: Bandwidth and Latency
GPUDirect offers optimized data transfer by enabling direct GPU-to-GPU communication, significantly reducing latency compared to traditional RDMA, which relies on CPU mediation in many cases. In terms of bandwidth, GPUDirect leverages PCIe and NVLink pathways to achieve higher throughput, often exceeding RDMA's network-based transfer rates, especially in multi-GPU and high-performance computing scenarios. Latency improvements with GPUDirect can reach microsecond-level reductions, enabling faster GPU communication critical for deep learning and real-time data processing workloads.
Hardware and Software Requirements
GPUDirect enables direct data transfers between GPUs and third-party devices through PCIe, requiring NVIDIA GPUs with GPUDirect support and compatible InfiniBand or NIC hardware. RDMA facilitates low-latency, high-throughput communication by allowing direct memory access between remote systems, demanding network interface cards (NICs) with RDMA capabilities, such as InfiniBand or RoCE, and driver support on host systems. Both technologies rely on specific hardware, like NVIDIA GPUs for GPUDirect and RDMA-capable NICs, and software drivers that integrate with operating systems to optimize data transfer paths and minimize CPU involvement.
Integration with HPC and AI Workloads
GPUDirect enables direct memory access between GPUs and third-party devices, significantly reducing latency and CPU overhead in HPC and AI workloads, enhancing data transfer speed and efficiency. RDMA (Remote Direct Memory Access) allows direct memory access from one computer to another without involving the CPU, facilitating low-latency, high-throughput network communication critical for distributed HPC and AI training. Integration of GPUDirect with RDMA accelerates multi-node AI model training by combining GPU memory access optimization with high-performance network communication, maximizing scalability and performance in large-scale HPC and AI systems.
Security and Data Integrity Considerations
GPUDirect and RDMA both facilitate high-speed data transfers, but GPUDirect enhances security by enabling direct GPU memory access, reducing exposure to intermediate system buffers prone to attacks. RDMA offloads data transfer to network adapters, minimizing CPU involvement, which improves data integrity through lower latency and fewer data copy operations, but requires careful configuration to prevent unauthorized access. Ensuring robust encryption, authentication protocols, and hardware isolation is critical in both technologies to maintain secure and reliable data communication in HPC and AI workloads.
Future Trends in GPUDirect and RDMA Technologies
Future trends in GPUDirect and RDMA technologies emphasize enhanced low-latency, high-bandwidth data transfer capabilities critical for next-generation AI and HPC workloads. Integration of GPUDirect with advanced RDMA protocols aims to optimize direct GPU-to-GPU communication across distributed systems, reducing CPU overhead and improving scalability. Emerging developments focus on expanding support for heterogeneous computing environments, increasing compatibility with cloud infrastructures, and leveraging hardware innovations to accelerate real-time data processing.
Zero-copy data transfer
GPUDirect enables zero-copy data transfer by directly accessing GPU memory for reduced latency, while RDMA facilitates zero-copy transfers across network interfaces bypassing CPU involvement for efficient remote memory access.
PCIe peer-to-peer
GPUDirect enables direct PCIe peer-to-peer data transfers between GPUs and network interfaces, reducing latency compared to RDMA, which primarily facilitates remote memory access over networks without leveraging direct PCIe paths.
NVLink
NVLink enhances GPUDirect by providing high-bandwidth, low-latency GPU-to-GPU communication, outperforming traditional RDMA by enabling faster data transfer through direct GPU memory access.
Direct memory access (DMA)
GPUDirect enables direct memory access (DMA) between GPUs and third-party devices to reduce latency, while RDMA facilitates zero-copy DMA across networked systems for efficient remote data transfer.
CUDA-aware MPI
CUDA-aware MPI leverages GPUDirect RDMA technology to enable direct GPU-to-GPU data transfers, significantly reducing latency and CPU overhead in high-performance computing applications.
Memory registration
GPUDirect enables direct GPU memory access bypassing host memory but requires explicit GPU memory registration, whereas RDMA relies on registering and pinning host memory buffers for zero-copy data transfers.
Scatter-gather I/O
GPUDirect enables efficient Scatter-gather I/O by allowing GPUs to directly access network data buffers, reducing latency compared to RDMA which primarily benefits CPU-to-CPU transfers.
Infiniband fabric
GPUDirect enables direct memory access between GPUs and Infiniband fabric using RDMA to reduce latency and CPU overhead in high-performance computing applications.
GPU memory mapping
GPUDirect enables direct GPU memory access over PCIe for reduced latency, while RDMA provides network-based remote GPU memory mapping, both enhancing data transfer efficiency between GPUs and external devices.
Remote peer access
GPUDirect enables direct GPU-to-GPU communication within a node, while RDMA facilitates efficient remote peer access by allowing GPUs to read and write memory across networked nodes with low latency and minimal CPU involvement.
GPUDirect vs RDMA Infographic