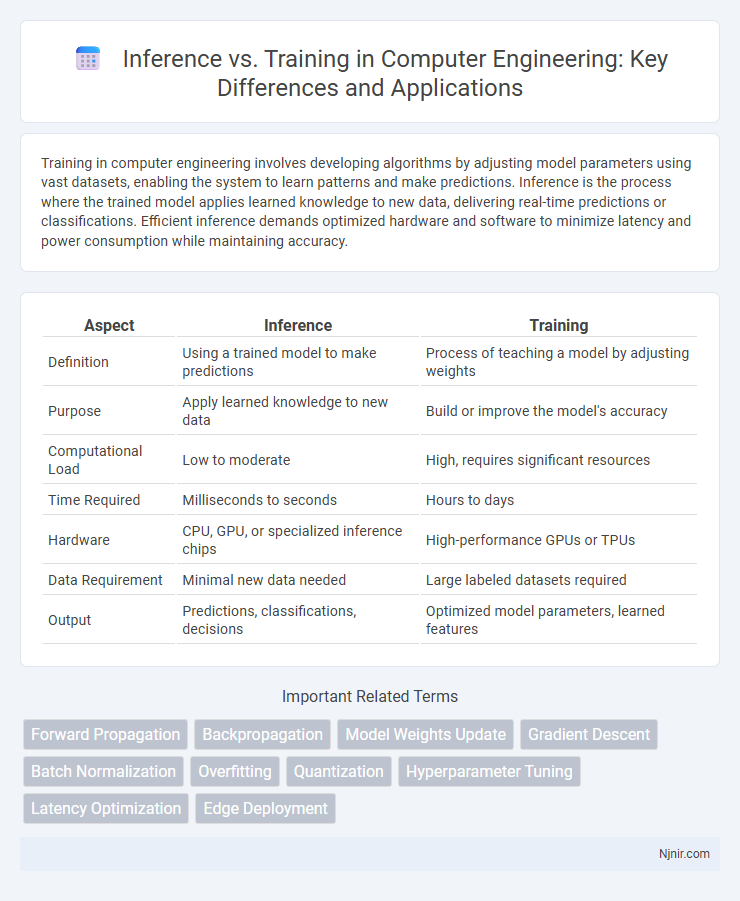
Training in computer engineering involves developing algorithms by adjusting model parameters using vast datasets, enabling the system to learn patterns and make predictions. Inference is the process where the trained model applies learned knowledge to new data, delivering real-time predictions or classifications. Efficient inference demands optimized hardware and software to minimize latency and power consumption while maintaining accuracy.
Table of Comparison
| Aspect | Inference | Training |
|---|---|---|
| Definition | Using a trained model to make predictions | Process of teaching a model by adjusting weights |
| Purpose | Apply learned knowledge to new data | Build or improve the model's accuracy |
| Computational Load | Low to moderate | High, requires significant resources |
| Time Required | Milliseconds to seconds | Hours to days |
| Hardware | CPU, GPU, or specialized inference chips | High-performance GPUs or TPUs |
| Data Requirement | Minimal new data needed | Large labeled datasets required |
| Output | Predictions, classifications, decisions | Optimized model parameters, learned features |
Introduction to Inference and Training in Computer Engineering
Inference in computer engineering involves deploying a trained machine learning model to make predictions or decisions based on new input data, emphasizing fast and efficient processing. Training is the computationally intensive process where algorithms iteratively adjust model parameters using large datasets to minimize error and improve accuracy. Understanding the distinction between inference and training is critical for optimizing resource allocation, as training demands high-performance hardware for parallel computation while inference prioritizes low-latency execution on edge or production devices.
Core Concepts: What is Training?
Training is the process of teaching a machine learning model to recognize patterns by feeding it large datasets and adjusting its internal parameters to minimize errors. This iterative procedure involves optimizing weights within neural networks using algorithms like gradient descent to improve prediction accuracy. Effective training requires substantial computational resources and carefully labeled data to ensure the model generalizes well to new inputs.
Core Concepts: What is Inference?
Inference is the process of using a trained machine learning model to make predictions or decisions based on new, unseen data. It involves applying the learned patterns and parameters from the training phase to input data, enabling real-time or batch prediction without further model adjustment. Efficient inference is critical for deploying AI models in production environments where low latency and high accuracy are essential.
Algorithmic Differences Between Training and Inference
Training involves iterative optimization algorithms such as gradient descent to update model parameters by minimizing a loss function using large datasets, whereas inference executes a fixed set of operations to generate predictions for new inputs without parameter updates. Training requires computationally intensive backpropagation steps to calculate gradients, while inference relies on forward propagation through the trained model to efficiently produce outputs. Algorithmically, training focuses on learning model parameters through error signal propagation, but inference applies the pre-learned model solely for prediction tasks.
Hardware Requirements: Training vs Inference
Training requires high-performance hardware with powerful GPUs or TPUs to process large datasets and perform complex computations over extended periods, emphasizing memory capacity and parallel processing capability. Inference demands less computational power, often running on optimized CPUs, edge devices, or specialized accelerators to efficiently execute pre-trained models with low latency and minimal energy consumption. The distinct hardware requirements reflect training's focus on model optimization and inference's emphasis on real-time prediction and deployment scalability.
Performance Metrics for Inference and Training
Inference performance metrics primarily include latency, throughput, and accuracy, measuring how quickly and accurately a trained model makes predictions on new data. Training performance metrics focus on convergence rate, loss reduction, and computational efficiency, reflecting how effectively a model learns from the training dataset. Both sets of metrics are crucial for optimizing deep learning workflows, with inference emphasizing real-time prediction speed and training emphasizing iterative improvement and resource utilization.
Energy Efficiency Considerations
Inference consumes significantly less energy compared to training since it involves running a pre-trained model for predictions rather than updating model parameters through backpropagation. Training requires extensive computational resources, often involving GPUs or TPUs operating over extended periods, leading to higher energy consumption and carbon footprint. Optimizing models for energy-efficient inference through techniques like quantization and pruning can substantially reduce power usage in deployment scenarios.
Real-Time Applications: Inference at the Edge
Inference at the edge enables real-time applications by processing data locally on devices such as smartphones, IoT sensors, and autonomous vehicles, reducing latency and bandwidth usage significantly. Training involves complex model adjustments requiring powerful cloud servers, whereas edge inference uses pre-trained models optimized for low-power environments to deliver instant predictions. This approach is essential for time-sensitive tasks like facial recognition, predictive maintenance, and augmented reality, where immediate response is crucial.
Security and Privacy in Training vs Inference
Training processes large datasets, increasing exposure to sensitive information and heightening privacy risks, making robust encryption and access controls essential for securing data during model development. Inference, typically operating on individual queries, involves less data volume but requires safeguards like differential privacy and secure model deployment to prevent leakage of sensitive model parameters or user inputs. Both stages demand tailored security measures to protect data integrity and confidentiality, with training focusing on data-centric protections and inference emphasizing real-time response security.
Future Trends in Inference and Training Technologies
Future trends in inference and training technologies emphasize edge computing advancements, enabling real-time AI processing with reduced latency and energy consumption. Techniques like federated learning and decentralized training enhance privacy while distributing computational loads across devices. Moreover, innovations in hardware accelerators, such as neuromorphic chips and AI-specific GPUs, are driving faster, more efficient model training and inference at scale.
Forward Propagation
Forward propagation in inference rapidly computes model outputs by passing input data through trained network layers, while in training it simultaneously supports error calculation for weight updates.
Backpropagation
Backpropagation is a key algorithm used during training to optimize neural network weights by propagating error gradients, while inference uses the trained weights to make predictions without updating them.
Model Weights Update
Inference uses fixed model weights to generate predictions, while training involves continuous model weights updates through backpropagation and gradient descent.
Gradient Descent
Gradient descent optimizes model parameters during training by iteratively minimizing loss, whereas inference uses the fixed trained parameters to make predictions without updating weights.
Batch Normalization
Batch Normalization improves training stability by normalizing activations using batch statistics, while during inference it applies fixed mean and variance estimates to ensure consistent performance.
Overfitting
Inference uses a trained model to make predictions without updating parameters, while training optimizes model parameters and risks overfitting by fitting noise instead of general patterns.
Quantization
Quantization reduces model size and improves inference speed by representing weights with lower precision, while training typically uses higher precision to maintain accuracy during gradient updates.
Hyperparameter Tuning
Hyperparameter tuning significantly impacts training performance by optimizing model parameters before inference, ensuring improved accuracy and efficiency during real-time prediction tasks.
Latency Optimization
Inference latency optimization involves minimizing response time by employing techniques such as model quantization, pruning, and hardware acceleration, whereas training focuses on maximizing learning efficiency and accuracy over extended periods.
Edge Deployment
Edge deployment requires optimized inference models that prioritize low latency and reduced computational resources over the extensive data processing and iterative optimization characteristic of training.
Inference vs Training Infographic