TensorRT offers highly optimized performance for NVIDIA GPUs, enabling efficient deep learning inference with reduced latency and increased throughput. OpenVINO supports a broader range of hardware, including Intel CPUs, VPUs, and FPGAs, facilitating flexible deployment across diverse edge devices. Both frameworks accelerate AI workloads, but TensorRT excels in NVIDIA-centric environments while OpenVINO provides versatility for heterogeneous hardware platforms.
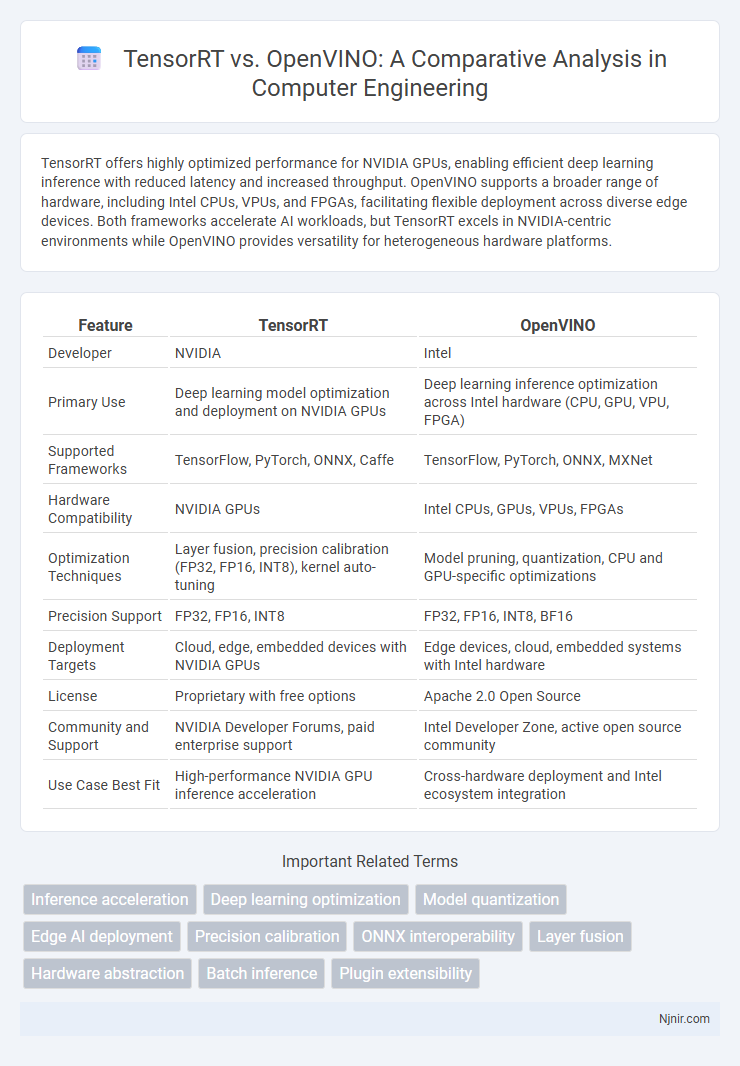
Table of Comparison
| Feature | TensorRT | OpenVINO |
|---|---|---|
| Developer | NVIDIA | Intel |
| Primary Use | Deep learning model optimization and deployment on NVIDIA GPUs | Deep learning inference optimization across Intel hardware (CPU, GPU, VPU, FPGA) |
| Supported Frameworks | TensorFlow, PyTorch, ONNX, Caffe | TensorFlow, PyTorch, ONNX, MXNet |
| Hardware Compatibility | NVIDIA GPUs | Intel CPUs, GPUs, VPUs, FPGAs |
| Optimization Techniques | Layer fusion, precision calibration (FP32, FP16, INT8), kernel auto-tuning | Model pruning, quantization, CPU and GPU-specific optimizations |
| Precision Support | FP32, FP16, INT8 | FP32, FP16, INT8, BF16 |
| Deployment Targets | Cloud, edge, embedded devices with NVIDIA GPUs | Edge devices, cloud, embedded systems with Intel hardware |
| License | Proprietary with free options | Apache 2.0 Open Source |
| Community and Support | NVIDIA Developer Forums, paid enterprise support | Intel Developer Zone, active open source community |
| Use Case Best Fit | High-performance NVIDIA GPU inference acceleration | Cross-hardware deployment and Intel ecosystem integration |
Introduction to TensorRT and OpenVINO
TensorRT, developed by NVIDIA, is a high-performance deep learning inference optimizer and runtime library designed to accelerate neural network deployment on NVIDIA GPUs, maximizing throughput and minimizing latency. OpenVINO, by Intel, is an open-source toolkit that facilitates the optimization and deployment of deep learning models across Intel hardware, including CPUs, integrated GPUs, and VPUs, enhancing inference speed and efficiency. Both frameworks support popular deep learning models but target different hardware ecosystems, offering specialized optimizations for their respective platforms.
Supported Hardware and Platform Compatibility
TensorRT excels in NVIDIA GPU support, optimizing deep learning models primarily for NVIDIA's CUDA platform, including RTX and Tesla series, making it ideal for high-performance AI inference on NVIDIA hardware. OpenVINO offers broad hardware compatibility, supporting Intel CPUs, integrated GPUs, VPUs like the Intel Movidius, and FPGAs, enhancing AI inference across edge devices and Intel's ecosystem. Platform compatibility for TensorRT centers on Linux and Windows with CUDA-enabled GPUs, whereas OpenVINO supports multiple operating systems, including Linux, Windows, and macOS, facilitating flexible deployment across diverse Intel-based platforms.
Model Compatibility and Supported Frameworks
TensorRT offers optimized support primarily for NVIDIA GPU-accelerated frameworks such as TensorFlow, PyTorch, and ONNX models, excelling in deep learning inference for NVIDIA hardware. OpenVINO provides broad compatibility with Intel hardware and supports frameworks like TensorFlow, Caffe, and ONNX, enabling seamless deployment across CPUs, VPUs, and FPGAs. Model compatibility in TensorRT is tightly integrated with NVIDIA's ecosystem, while OpenVINO emphasizes cross-platform versatility and heterogeneous compute support.
Performance Benchmarks: Speed and Latency
TensorRT delivers superior speed and lower latency in optimizing NVIDIA GPU models, achieving up to 40% faster inference compared to alternative frameworks. OpenVINO excels in Intel hardware environments, particularly with CPU and VPU acceleration, often reducing latency by 30% in edge AI applications. Benchmark tests reveal TensorRT's advantage in high-throughput scenarios, while OpenVINO provides efficient real-time performance on diverse Intel architectures.
Precision Support: FP32, FP16, INT8, and Others
TensorRT supports FP32, FP16, and INT8 precisions with optimized hardware acceleration for NVIDIA GPUs, delivering high inference speed and energy efficiency. OpenVINO offers extensive precision support, including FP32, FP16, BF16, and INT8, optimized for Intel CPUs, integrated GPUs, VPUs, and FPGAs, enabling flexible deployment across various Intel hardware. Both frameworks leverage quantization techniques and precision calibration to balance performance, accuracy, and resource utilization in AI inference workloads.
Ease of Model Conversion and Deployment
TensorRT provides streamlined model conversion primarily for NVIDIA-optimized frameworks like TensorFlow and PyTorch, enabling efficient deployment on NVIDIA GPUs with minimal manual adjustments. OpenVINO supports a wider range of frameworks including TensorFlow, ONNX, and Caffe, offering an intuitive Model Optimizer that simplifies the conversion process for diverse hardware such as Intel CPUs, GPUs, and VPUs. Both platforms emphasize ease of deployment, but TensorRT excels in NVIDIA hardware integration while OpenVINO shines in heterogeneous hardware support and flexible, user-friendly model conversion tools.
Integration with Popular Deep Learning Frameworks
TensorRT integrates seamlessly with popular deep learning frameworks such as TensorFlow and PyTorch through its native parsers and ONNX support, enabling efficient model optimization and deployment on NVIDIA GPUs. OpenVINO offers robust compatibility with frameworks like TensorFlow, PyTorch, and Caffe, leveraging its Model Optimizer to convert models into an intermediate representation for inference acceleration on Intel hardware. Both platforms facilitate streamlined workflow integration, but TensorRT is optimized for NVIDIA GPU ecosystems while OpenVINO targets Intel CPUs, integrated GPUs, and VPUs.
Community Support and Documentation
TensorRT benefits from extensive NVIDIA developer community support and comprehensive documentation tailored for optimizing deep learning models on NVIDIA GPUs. OpenVINO offers robust resources backed by Intel, including detailed guides and an active forum focused on deploying AI workloads across Intel hardware. Both platforms maintain strong documentation and community engagement, but TensorRT's NVIDIA ecosystem often provides faster updates and more specialized GPU optimization tips.
Use Cases in Edge and Cloud Deployments
TensorRT excels in optimizing deep learning models for NVIDIA GPUs, making it ideal for edge devices requiring high-throughput inference and real-time performance such as autonomous vehicles and video analytics. OpenVINO specializes in deploying AI applications on Intel hardware across edge and cloud environments, enabling efficient inference on CPUs, VPUs, and FPGAs, which suits scenarios like smart cameras and industrial IoT. Both frameworks support cloud deployments but TensorRT's compatibility with NVIDIA GPU instances offers superior acceleration for complex neural networks in large-scale cloud services.
Conclusion: Choosing the Right Inference Engine
TensorRT excels in maximizing performance on NVIDIA GPUs, offering optimized support for deep learning frameworks like TensorFlow and PyTorch, making it ideal for applications requiring high-throughput and low-latency inference on NVIDIA hardware. OpenVINO delivers broad hardware compatibility, including Intel CPUs, integrated GPUs, and VPUs, with strong model optimization capabilities suited for edge deployments and heterogeneous environments. Selecting the right inference engine depends on the target hardware ecosystem, specific performance needs, and deployment constraints, with TensorRT favored for NVIDIA-centric setups and OpenVINO preferred for Intel-based or multi-platform scenarios.
Inference acceleration
TensorRT delivers superior GPU-accelerated inference speed for NVIDIA hardware, while OpenVINO optimizes cross-platform CPU and Intel-specific accelerators for enhanced inference performance in computer vision applications.
Deep learning optimization
TensorRT delivers optimized deep learning inference primarily for NVIDIA GPUs, while OpenVINO enhances model deployment across Intel hardware by accelerating deep learning workloads with extensive support for CPUs, VPUs, and FPGAs.
Model quantization
TensorRT offers highly optimized INT8 and FP16 model quantization for NVIDIA GPUs to accelerate inference with minimal precision loss, while OpenVINO provides extensive INT8 model quantization support across Intel CPUs, GPUs, and VPUs to enhance deployment flexibility and efficiency.
Edge AI deployment
TensorRT offers high-performance deep learning inference optimized for NVIDIA GPUs in Edge AI deployments, while OpenVINO provides versatile acceleration across Intel hardware, including CPUs, VPUs, and FPGAs, enabling efficient Edge AI application deployment.
Precision calibration
TensorRT excels in precision calibration with INT8 optimization using extensive heuristic search and calibration caches for NVIDIA GPUs, while OpenVINO provides versatile quantization tools supporting INT8 and FP16 precision calibration optimized for Intel hardware accelerators.
ONNX interoperability
TensorRT offers optimized ONNX model deployment primarily for NVIDIA GPUs, achieving high inference speed and efficiency, while OpenVINO provides broad ONNX compatibility with hardware acceleration across Intel CPUs, GPUs, and VPUs, enabling flexible edge and cloud deployment.
Layer fusion
TensorRT achieves superior layer fusion optimization by combining compatible operations into single kernels for NVIDIA GPUs, while OpenVINO optimizes layer fusion primarily for Intel hardware through targeted graph transformations enhancing CPU and VPU execution efficiency.
Hardware abstraction
TensorRT offers optimized inference primarily for NVIDIA GPUs, while OpenVINO provides broader hardware abstraction by supporting various Intel devices including CPUs, GPUs, VPUs, and FPGAs for versatile deployment.
Batch inference
TensorRT delivers higher batch inference throughput and lower latency on NVIDIA GPUs, while OpenVINO optimizes batch processing efficiency on Intel hardware with extensive support for heterogeneous accelerators.
Plugin extensibility
TensorRT offers extensive plugin extensibility for custom layer integration, while OpenVINO provides flexible plugin support tailored for Intel hardware acceleration.
TensorRT vs OpenVINO Infographic