A data historian specializes in capturing, storing, and analyzing time-series data from industrial processes with high precision, ensuring real-time monitoring and historical traceability. In contrast, a data lake stores vast amounts of raw, unstructured data from diverse sources, enabling flexible, large-scale analytics across multiple domains beyond industrial operations. Choosing between a data historian and a data lake depends on the specific needs for data structure, speed, and analytical scope in industrial engineering processes.
Table of Comparison
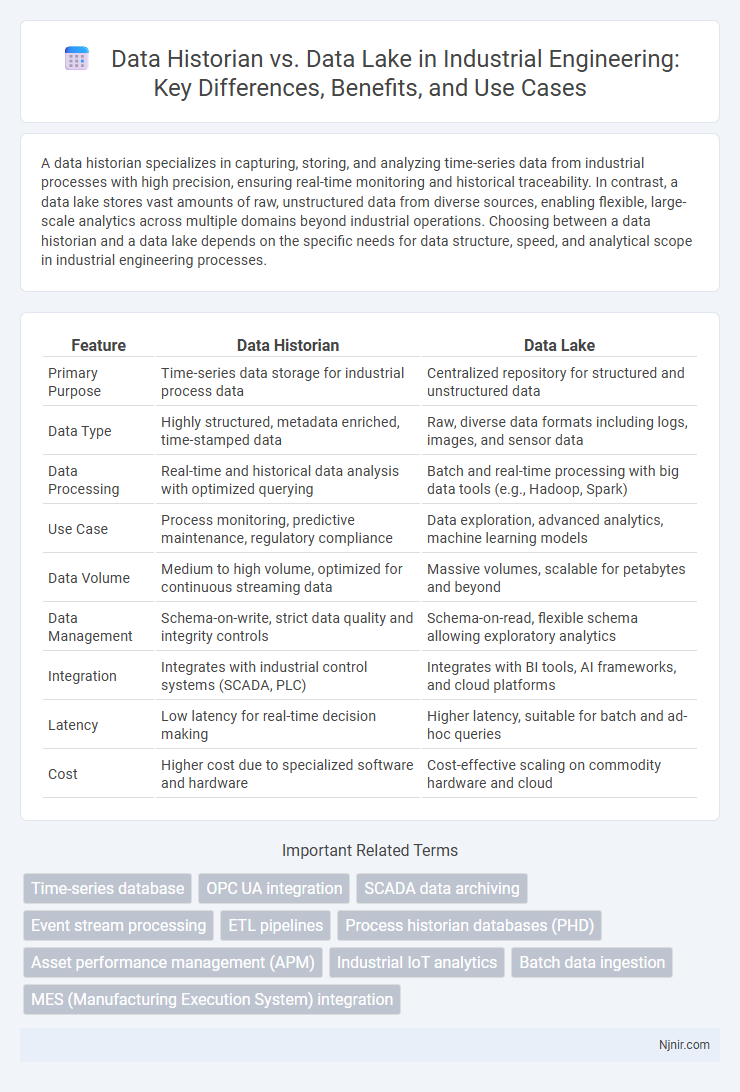
| Feature | Data Historian | Data Lake |
|---|---|---|
| Primary Purpose | Time-series data storage for industrial process data | Centralized repository for structured and unstructured data |
| Data Type | Highly structured, metadata enriched, time-stamped data | Raw, diverse data formats including logs, images, and sensor data |
| Data Processing | Real-time and historical data analysis with optimized querying | Batch and real-time processing with big data tools (e.g., Hadoop, Spark) |
| Use Case | Process monitoring, predictive maintenance, regulatory compliance | Data exploration, advanced analytics, machine learning models |
| Data Volume | Medium to high volume, optimized for continuous streaming data | Massive volumes, scalable for petabytes and beyond |
| Data Management | Schema-on-write, strict data quality and integrity controls | Schema-on-read, flexible schema allowing exploratory analytics |
| Integration | Integrates with industrial control systems (SCADA, PLC) | Integrates with BI tools, AI frameworks, and cloud platforms |
| Latency | Low latency for real-time decision making | Higher latency, suitable for batch and ad-hoc queries |
| Cost | Higher cost due to specialized software and hardware | Cost-effective scaling on commodity hardware and cloud |
Defining Data Historians in Industrial Engineering
Data historians in industrial engineering are specialized databases designed to capture, store, and retrieve time-series data generated by industrial processes and equipment, enabling real-time monitoring and historical analysis. Unlike data lakes that store diverse and unstructured data from multiple sources for broad analytics, data historians optimize high-frequency, timestamped sensor readings for rapid querying and process optimization. They play a critical role in predictive maintenance, process control, and compliance reporting by providing reliable, high-resolution historical records essential for operational decision-making.
Understanding Data Lakes in Industrial Environments
Data lakes in industrial environments store vast amounts of raw, diverse data from various sources like sensors, machines, and enterprise systems, enabling advanced analytics and machine learning applications. Unlike data historians, which specialize in time-series data from industrial operations with structured, high-frequency logging, data lakes provide scalable storage and flexible data ingestion for both structured and unstructured data types. This flexibility allows industries to integrate real-time operational data with contextual business information, supporting comprehensive insights and innovation in smart manufacturing.
Core Functional Differences Between Data Historians and Data Lakes
Data historians specialize in time-series data collection, storage, and retrieval tailored for industrial process monitoring, ensuring high data integrity and real-time analysis capabilities. Data lakes accommodate vast, unstructured datasets from varied sources, designed for flexible querying and big data analytics without rigid schema constraints. While data historians emphasize operational data accuracy and performance, data lakes prioritize scalability and multi-format data storage for broader analytical applications.
Data Collection Methods: Historian vs. Lake
Data historians collect and store time-series data from industrial control systems using structured extraction methods that capture high-frequency, timestamped events for real-time monitoring and analysis. Data lakes ingest raw, unstructured, and semi-structured data from diverse sources through batch or streaming pipelines, accommodating volumes at scale without predefined schema constraints. The historian emphasizes precise, optimized data capture tailored for operational technology, while data lakes prioritize broad data variety and flexible ingestion for enterprise-wide analytics.
Data Structure and Storage Approaches
Data historians utilize time-series databases optimized for capturing, storing, and retrieving sequential industrial data with high compression and real-time access. Data lakes store vast amounts of structured, semi-structured, and unstructured data in their raw format, enabling flexible schema-on-read approaches. While data historians emphasize efficient, indexed time-stamped data storage for process monitoring, data lakes prioritize scalability and diverse data integration for advanced analytics.
Real-Time Data Access and Analytics Capabilities
Data historians specialize in real-time data access by capturing and storing high-frequency operational data from industrial equipment with time-stamped precision, enabling immediate analysis and quick decision-making. Data lakes provide scalable storage for vast volumes of structured and unstructured data, but often lack the optimized real-time indexing and querying capabilities that a data historian offers for instantaneous analytics. Real-time analytics in data lakes typically require additional processing layers or integration with real-time data platforms to match the performance of data historians in time-sensitive industrial environments.
Scalability and Integration with Industrial Systems
Data historians excel in real-time, time-series data storage with built-in support for industrial protocols, offering seamless integration with SCADA and DCS systems but may face limitations in horizontal scalability. Data lakes provide vast scalability through distributed storage architectures, accommodating diverse industrial data types, yet require additional middleware or connectors for effective integration with legacy industrial equipment. Choosing between them depends on the need for real-time industrial system compatibility versus large-scale, diverse data storage and analysis.
Security and Compliance in Data Management
Data historians offer robust security features tailored for industrial environments, including encrypted data storage, user authentication, and audit trails that ensure regulatory compliance with standards like ISA-95 and FDA 21 CFR Part 11. Data lakes provide scalable storage for diverse data types but require additional security frameworks such as role-based access control (RBAC), encryption at rest and in transit, and data governance policies to meet compliance requirements like GDPR and HIPAA. Effective data management strategies integrate the specialized, controlled environment of data historians with the flexible, large-scale capabilities of data lakes while maintaining stringent security and compliance standards.
Choosing the Right Solution: Use Cases in Industrial Engineering
Data historians excel in industrial engineering for real-time process monitoring, capturing time-series data with high precision and reliability, essential for predictive maintenance and operational efficiency. Data lakes offer scalable storage for diverse datasets, enabling advanced analytics and machine learning on historical and unstructured data to optimize production workflows. Selecting between a data historian and a data lake depends on specific use cases such as immediate control system feedback versus large-scale data integration for strategic decision-making.
Future Trends: Convergence and Innovation in Industrial Data Solutions
Data historian systems are evolving to integrate with data lakes, enabling seamless storage of high-fidelity time-series industrial data alongside diverse unstructured data formats. Future trends emphasize convergence through hybrid architectures that combine real-time operational insights from historians with advanced analytics and machine learning capabilities enabled by data lakes. This innovation drives more agile industrial data solutions, fostering predictive maintenance, enhanced process optimization, and comprehensive digital twin implementations.
Time-series database
A data historian is a specialized time-series database optimized for collecting, storing, and querying industrial process data with high-frequency timestamps, while a data lake is a scalable repository that stores raw time-series and non-time-series data from diverse sources without optimized time-series query capabilities.
OPC UA integration
Data historians excel in real-time OPC UA integration for industrial process monitoring with timestamped, high-resolution data, whereas data lakes offer scalable storage of diverse OPC UA-generated datasets for advanced analytics and flexible schema.
SCADA data archiving
Data historians provide optimized, time-series SCADA data archiving with high compression and fast retrieval, whereas data lakes store large, unstructured SCADA datasets for advanced analytics without specialized time-series indexing.
Event stream processing
Data historians specialize in time-series event stream processing for industrial operations by efficiently capturing and storing high-frequency sensor data, whereas data lakes provide scalable, flexible storage for diverse event streams but require additional tools for real-time processing and analysis.
ETL pipelines
Data historians optimize structured industrial time-series data storage with streamlined ETL pipelines for real-time analysis, while data lakes handle vast, diverse raw datasets requiring complex ETL processes to support flexible analytics and machine learning.
Process historian databases (PHD)
Process Historian Databases (PHD) provide specialized, high-resolution time-series data storage and retrieval optimized for industrial process data, unlike generic data lakes which store large volumes of diverse, unstructured data without domain-specific schema or query performance.
Asset performance management (APM)
Data historians provide high-resolution, time-series asset data for real-time Asset Performance Management (APM), while data lakes aggregate diverse industrial datasets enabling advanced analytics for predictive maintenance and operational optimization.
Industrial IoT analytics
Data historians optimize time-series data storage for Industrial IoT analytics with high-frequency, reliable process data, while data lakes handle vast, diverse raw datasets enabling broader analytics and machine learning applications.
Batch data ingestion
Data historians specialize in structured batch data ingestion for time-series industrial data, whereas data lakes support scalable batch ingestion of diverse raw data types across various sources.
MES (Manufacturing Execution System) integration
Data historians store time-series data for MES integration with optimized real-time retrieval and aggregation, while data lakes offer scalable storage of diverse manufacturing data types for advanced analytics and machine learning.
Data historian vs Data lake Infographic